

 Vítejte, dnes je
středa
02.
duben
2025
Vítejte, dnes je
středa
02.
duben
2025
Obecně platí přesvědčení, že zdrojový kód ručně psaný v assembleru dá vždy nejlepší výsledek, přestože se jedná o časově náročný proces vyžadující značné znalosti. Tento článek zkoumá toto přesvědčení a na běžných situacích ukazuje, že použití vyššího programovacího jazyka, např. C, s moderním kompilátorem, může pravidelně dávat lepší výsledek. Částečně je to záležitost pochopení optimalizací v kompilátoru a generování kódu a částečně záležitost pochopení lidské povahy.
Všichni víme, že nejlepší způsob, jak získat rychlý, úsporný kód pro embedded aplikaci, je využít schopností profesionálního programátora v assembleru. Takový programátor musí samozřejmě znát architekturu daného zařízení, jeho sadu instrukcí i assembler a tyto znalosti musí do aplikace komplexně včlenit. Je zřejmé, že kompilátor zde nemůže konkurovat, protože není v žádném případě schopný postihnout přesné požadavky aplikace.
Zní to jako rozumná úvaha, která ale nebere v potaz jeden faktor: lidskou povahu. K té se vrátíme později.
Moderní embedded kompilátory jsou extrémně dobré. Kompilátor typicky využívá širokou škálu optimalizací, vývojáři nabízí detailní kontrolu nad generovaným kódem. Kompilátory také v kódu vyhledávají vzory, což může vést k optimálnímu překladu.
Abychom zjistili, jak kompilátory přistupují k typickému embedded kódu, podíváme se na příkazy switch v jazyce C. Příkaz switch může zhruba mít jednu ze čtyř forem:
Podíváme se postupně na každou z těchto forem. Příklady jsou vybudovány pomocí produktu Sourcery CodeBench od společnosti Mentor Embedded pro mikroprocesor Coldfire s minimální optimalizací, abychom získali čitelný kód. Vybral jsem si tento procesor, protože jeho assembler je poměrně čitelný. Předpokládám, že použití kompilátorů od jiných výrobců by přineslo podobné výsledky.
Je-li pro konstrukci příkazů if/else logika příliš spletitá, použijeme obvykle příkaz switch. Normálně v této situaci existuje pouze malý počet hodnot case, například:

Pro většinu architektur CPU je účinným způsobem, jak zacházet s touto logikou, použití několika diskrétních porovnání a skoků. Výsledkem je kód podobný následujícímu, kde %d0 je použito místo x:

Jindy můžeme použít mnohem větší počty hodnot case. Většina kompilátorů počet hodnot neomezuje, ale jsou zde silné argumenty proti příliš vysokému číslu, protože tím trpí čitelnost kódu. Někdy jsou hodnoty case souvislé, například:

Kompilátor tento vzor odhalí a vygeneruje zhruba tento kód:
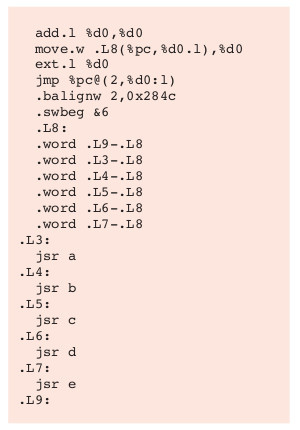
Kód používá hodnotu x k indexování tabulky skoků. Je to mnohem rychlejší než provádět dlouhou sekvenci porovnávání. Je jasné, že počet hodnot case, od kterého je tento přístup efektivnější, se bude lišit podle dané sady instrukcí.
Další možností je případ, kdy je sekvence hodnot case téměř souvislá, například:

Kompilátor opět rozpozná sekvenci a vytvoří tabulku skoků:

Tentokrát tabulka obsahuje fiktivní položku, která kompenzuje „chybějící“ hodnotu case.
Poslední možností je případ, kdy máme značně vysoký počet hodnot case bez výraznějšího vzoru, například:

V mých testech se kompilátor vrátil k sekvenci porovnání, takže výsledkem je:

Zajímavé je, že kompilátor ví, že při větších počtech hodnot může snížit počet porovnání jejich rozdělením do dvou skupin a provedením „nízkých“ a „vysokých“ hodnot separátně. I když k tomu nedošlo v mých testech (které nebyly důsledné, ale provedl jsem je i pro ARM a X86), jsem si jistý, že pro některé architektury může pro tyto případy být účinnější jiná strategie generování kódu, a to vyhledávací tabulka hodnot a adres.
Takže, jak by se lidský programátor vypořádal s kódováním těchto čtyř druhů struktury příkazu case? Jak jsem již řekl, pokud budeme mít v týmu profesionály, můžeme očekávat, že jejich řešení bude minimálně stejné jako s kompilátorem, či spíše lepší.
To je však nepravděpodobné. Zkušený programátor by měl vědět, že je dobrým zvykem psát udržovatelný kód, i za cenu určitého snížení výkonu/efektivity. Využití souvislé (nebo téměř souvislé) sekvence hodnot case k indexování tabulky skoků je špatný způsob, protože tato struktura nemusí podporovat případnou budoucí změnu softwaru. Žádný lidský programátor se nebude chtít vystavovat riziku, že bude muset přepsat část kódu, když dojde v budoucnu ke změnám v projektu. Programátor bude psát takový kód defenzivním způsobem.
Kompilátoru ovšem nevadí opakované překládání kódu, takže s největší pravděpodobností vyprodukuje vždy optimální výsledek. Nicméně příkaz switch v kódu vytvořeném v jazyce C je udržovatelný velmi dobře, takže dává smysl psát programy ve vyšším programovacím jazyku, kdykoliv je to možné.
Dodatek: Když jsem psal tento článek, vzpomněl jsem si na svoje rané zkušenosti s embedded softwarem, který se programoval ve Forthu. V těch dobách se věřilo, že takovéto zřetězené interpretační jazyky mohou pro danou funkcionalitu vygenerovat menší velikost kódu než assembler. Díval jsem se na to skepticky, ale testy nám ukázaly, že pro rozumně velkou aplikaci tomu tak opravdu je. Výkon za běhu programu (nebo spíše jeho nedostatek) byl hlavní vadou takového kompaktního kódu. I když u moderních zařízení můžeme rychlost běhu programu považovat za dostatečnou, povaha „read only“ kódu Forthu a z ní plynoucí problémy s údržbou ze mě dělají pesimistu ohledně jeho návratu v blízké budoucnosti.
Zdroj: Is assembly language best?,
www.embedded.com, 14. 12. 2012.














