

 Vítejte, dnes je
středa
02.
duben
2025
Vítejte, dnes je
středa
02.
duben
2025
Následující článek se snaží přiblížit základní výhody obvodů FPGA při vývoji softwaru v oblasti embedded systémů. Při vývoji náročných aplikací je třeba zvážit velké množství faktorů, ovlivňujících zvolenou výpočetní platformu (mikrokontrolér, digitální signálový procesor, jednodeskový počítač atd.).
V zásadě převažují tyto parametry:
Vzhledem k tomu, že primárním zaměřením článku je „zrychlení software“, nebudeme zde uvažovat systémy, které lze realizovat pomocí mikro-automatů z nižšího výkonnostního segmentu, ale poohlédneme se po takových systémech, které vyžadují dostatečný výpočetní výkon. Tedy takových, kde je software hlavní překážkou při zpracování v reálném čase.
Dalo by se uvažovat o použití v komunikačních systémech, kde je nejvyšší konec tvořen signálovým procesorem, zajišťujícím výpočet DSP algoritmů v reálném čase. V úvahu připadá kupříkladu aplikace modulu digitálního fotoaparátu, kde embedded systém zajišťuje aplikaci některých před-algoritmů přímo na surová obrazová data ze snímače ještě před tím, než dojde k jejich přenosu do externího zařízení například po síti Ethernet. Stejně tak bychom mohli uvažovat intenzivní výpočetní algoritmy kontrolní smyčky v případě ovládání dostupných náprav automatizačního robota. Třetím a zatím posledním příkladem by mohla být aplikace, kde procesor zajišťuje zpracování paketů ze sítě Ethernet. Pro jejich aplikaci je nutné, aby procesor vždy vypočítal hodnotu CRC – kontrolní součet, což je úkol, který v případě obecného procesoru vyžaduje příliš mnoho kroků a brání v dosažení vysoké datové propustnosti.
Zejména poslední uvedený příklad ukazuje klasickou situaci, ve které je cílené zrychlení softwaru v reálné aplikaci velmi žádané a ve které své uplatnění naleznou propracované DSP algoritmy.
Zásadním problémem implementace libovolného algoritmu nebo části softwaru je, že pro optimální výkon by bylo mnohem výhodnější použití specializované počítačové platformy. Jelikož toto v praxi není možné, využívají univerzální procesory Von Neumannovu architekturu. Stejně tak tuto platformu využívá i většina mikrokontrolérů a digitálních signálových procesorů.
Tyto procesory pracují sekvenčně a mají obvykle omezený počet datových cest (často pouze jedinou). Proto také nejsou ideálním kandidátem pro nasazení paralelních algoritmů.
V praxi bývá nedostatečný výpočetní výkon řešen nejčastěji použitím procesoru s vyšším výkonem. Takové řešení je výhodné pouze tehdy, pokud mohou být ještě splněny omezení týkající se především výrobních nákladů na systém.
Přesto existuje celá řada aplikací, u kterých ani nákup dalšího výpočetního výkonu nemůže pomoci v dosažení kýžených cílů (výkon v reálném čase při co nejnižších výrobních nákladech). Dostupné alternativy budou uvedeny v následujícím příkladu a postupně se k nim vrátíme ještě později.
Dejme tomu, že máme k dispozici aplikaci regulačních obvodů, kterou chceme řídit nápravy automatizačního robota. Cílem je vývoj řídicího zařízení, které bude s co nejnižšími výrobními náklady schopné ovládat co nejvíce náprav, jak je to za daných „real-time“ podmínek možné. Příslušné algoritmy regulačních smyček jsou za použití aritmetiky s plovoucí desetinnou čárkou napsané v jazyce C. První implementace ukazuje, že dostupný výpočetní výkon zvoleného mikroprocesoru (32bit s plovoucí desetinnou čárkou) je v reálném čase dostatečný k řízení pouze jediné nápravy. Aby toho nebylo málo, nebo řekněme z jiného pohledu, je cena zařízení pro řízení pouze jediné nápravy příliš vysoká.
Hlavní problém byl identifikován v použití výpočtů s plovoucí desetinnou čárkou. Algoritmus byl tedy přepracován do podoby matematických operací s pevnou desetinnou čárkou. Uvedený příklad algoritmu byl simulován pomocí systému Matlab/Simulink (http://www.mathworks. com) za použití Cílové knihovny (http://www.dspace.com) a generátoru kódu C. Vygenerovaný kód v jazyce C, který byl nyní založený striktně na použití aritmetických operací s pevnou desetinnou čárkou, umožňoval v reálném čase řízení až čtyř samostatných náprav (za použití stejného procesoru), což v praxi představuje výrazný nárůst výkonu.
Dále se v následujícím textu dostáváme již do situace řešení za použití dnešních obvodů FPGA (programovatelných hradlových polí), které jsou schopny vytvořit řídicí systém s ještě lepším poměrem ceny na nápravu. V další části tedy nabídneme krátký úvod do problematiky FPGA a vytvoříme jednoduchý přehled možností vytvoření embedded procesorů ve struktuře FPGA. Dále si také ukážeme, proč jsou obvody FPGA vhodnou volbou pro implementaci algoritmů, určených pro zpracování digitálního signálu.
V rozsahu tohoto článku není možné poskytnout podrobný úvod do technologie hradlových polí. Zjednodušeně řečeno se jedná o strukturu logických celků, složených ze základních buněk, které jsou organizovány v maticové struktuře a umožňují vzájemně libovolné propojení.
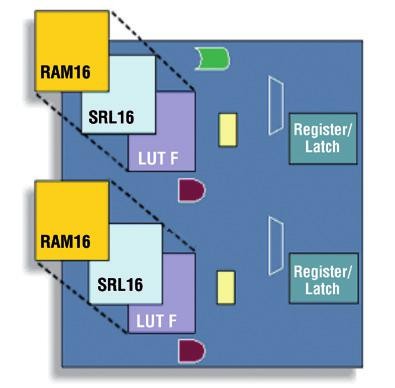
Obr. 1 Základní buňka FPGA Xilinx Virtex-II
Na obr. 1 je uveden příklad základní buňky na bázi SRAM v FPGA s LUT architekturou (Look-up Table). Rovněž jsou dostupné obvody FPGA s technologií Flash nebo dnes jsou stále dostupné dokonce i jednorázově programovatelné obvody s technologií pojistek (PROM). Jádrem obvodů jsou look-up tabulky (LUT), které si lze představit jako pravdivostní tabulky. Většina technologií vychází z LUT se čtyřmi vstupy a jedním výstupem, takže každá taková buňka je schopna zajistit booleovskou funkci čtyř proměnných. V základních buňkách jsou také obsaženy klopné obvody, záchytné registry, případně další zdroje, zajišťující realizaci speciálních struktur, jako jsou např. aritmetické obvody (sčítačky, komparátory…) s vysokým výkonem. V některých FPGA mohou být LUT konfigurovány rovněž jako 16bitové paměťové prvky nebo posuvné registry. V dnešních state-ofthe- art FPGA je podobných buněk obsaženo několik jednotek až stovek tisíc.
Všechny prvky se v FPGA obvodech konfigurují pomocí paměťových buněk. V případě FPGA na bázi SRAM je nutné všechny dostupné buňky inicializovat po každém zapnutí. K tomu se nejčastěji používají externí paměti (PROM, FLASH), ze kterých se po zapnutí „stáhne“ konfigurační bitový stream. Nejnovější technologie FPGA pak kromě základních buněk nabízí i řadu dalších speciálních zdrojů, jako jsou kupříkladu paměťové bloky, jádra typu ethernetových MAC kontrolérů, PowerPC či ARM jádra. Dokonce dnes nejsou výjimkou ani složité struktury pro digitální zpracování signálu v reálném čase.
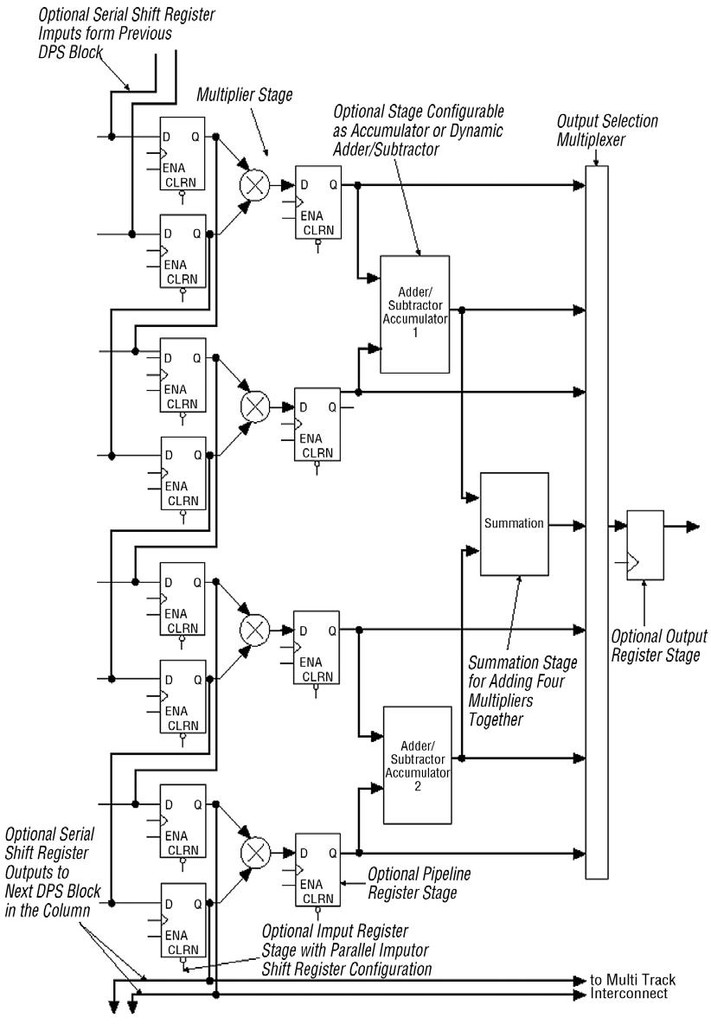
Obr. 2 DSP jednotka v FPGA Altera Stratix
V čem tedy spočívá případné zvýšení výkonu libovolné DSP aplikace? Podívejme se na rovnici filtru FIR s 16 průchody:
pro (i=0; i<16; i++)
{sum = sum+coeff[i]*data[i];}
Signálový procesor nebo mikrokontrolér s jedinou jednotkou MAC bude pro získání výsledku potřebovat mnohem více hodinových cyklů než FPGA, ve kterém může být realizováno 16 MAC jednotek. Proto jsou výpočty, aplikované na FPGA obvodech, nesrovnatelně rychlejší a vyžadují mnohem méně cyklů.
Před několika lety začali výrobci FPGA obvodů do svých produktů integrovat procesorová jádra. K dispozici jsou tak napevno připravené verze obsahující např. PowerPC či jádra ARM s přímou podporou soft-core řešení operačního systému např. Micro-Blaze (Xilinx) a NIOS (Altera). Výhodou je, že každé softwarové jádro umožňuje libovolnou parametrizaci a propojení s další logikou a integrovanými paměťovými zdroji, které nám dané FPGA nabízí. Srovnání výkonu NIOS a Micro- Blaze je velice vyrovnané, a proto v našem článku zůstaneme pouze u krátkého zhodnocení:
Oba výrobci nabízejí rozsáhlou softwarovou základnu a IP-Core balíčky, se kterými může uživatel mikrokontrolérové implementace snadno konfigurovat. Na rozdíl od standardních řešení (mikrokontrolérů a DSP), nejsou „soft“ mikrokontroléry nijak omezeny v množství ani typu integrovaných periferií. Pokud jsou v aplikaci potřeba například čtyři časovače místo dostupných tří, pak není nutné hledat jiný typ mikrokontroléru, ale stačí pouze zahrnout další časovač do implementace a připojit jej na procesorové jádro. Návrhová prostředí „SOPC-Builder“ (Altera) a „Platform-Studio“ (Xilinx) umožňují libovolnou konfiguraci vlastního mikrokontroléru, přesně podle požadavků dané aplikace.
Jak je vidět, jsou obvody FPGA přímo ideálním řešením pro softwarovou akceleraci. U embedded systému je pak třeba ještě rozhodnout, zda bude FPGA použit jako koprocesor, připojený k diskrétním mikroprocesorům/DSP, nebo zda bude mikroprocesor integrován přímo uvnitř FPGA. V každém případě se jedná o rozhodnutí, založené na optimální kombinaci HW a SW prostředků. Obvykle tak na vývoji podobných zařízení pracují i dvě samostatné skupiny vývojářů, zajišťujících realizaci hardware a software.
Otázkou je, zda jsou i zde potřeba dvě skupiny vývojářů. Většinou je odpověď jasné „ano“. Specializovaná skupina pracuje na vývoji software v nejrozšířenějších jazycích jako je C/C++ a požadavky na jejich odbornost jsou výrazně odlišné od požadavků potřebných k realizaci logické struktury obvodů FPGA. Zde se obvykle využívá specializovaných jazyků pro popis hardware, jako jsou VHDL, Verilog a další.
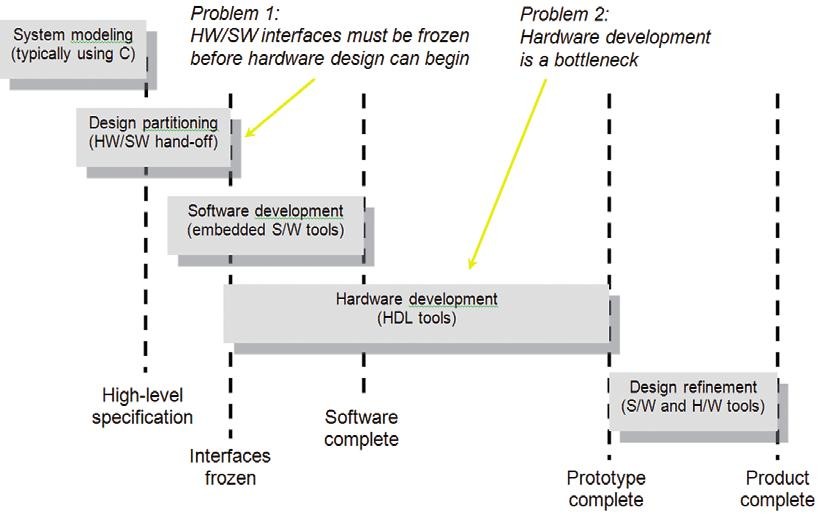
Obr. 3 Typická struktura HW a SW systému
Na obr. 3 je uvedena typická struktura systému, v němž jsou použity FPGA a samostatný procesor s firmware, který tvoří nezbytnou část systému.
V první fázi návrhu aplikace začínáme modelováním algoritmů jádra systému s tím, že celý proces začíná dělením na hardware a software. Výsledkem je např. proces profilování výkonu, který umožní selekci algoritmů mezi software provozované na procesorové platformě a mezi části, které budou z důvodu vysoké rychlosti zajištěny pomocí hardwaru (logických hradel). Výsledkem celého procesu je přesná specifikace rozdělení úloh na hardware a software, včetně určení rozhraní mezi oběma platformami. Navíc máme nyní přesně definované požadavky (bloky akcelerátoru) pro počítačovou platformu. Například v aplikaci pro zpracování obrazu může softwarový vývojář požádat o převod některých bloků z důvodu akcelerace do oblasti hardware, jako jsou bloky DCT, FFT nebo jiný speciální, velmi rychlý filtr.
Jakmile je pak dokončena definice rozhraní mezi hardware a software, může začít vývoj hardwaru. V závislosti na daném systému může být také návrh HW nebo naopak návrh SW v projektovém harmonogramu určen jako kritická část. V každém případě bývá obvykle časově velmi náročný vývoj HW, především pak ve chvíli návrhu specializovaných akceleračních bloků, které musí být vyvinuty a důkladně ověřeny (což bývá časově nejnáročnějším úkolem).
V další fázi vývoje bude již prototyp hardwarového řešení k dispozici a může být využit jako výchozí platforma pro vývoj softwaru a jeho validaci. Na konci tohoto procesu je již výsledný produkt. Tento procesní řetězec je dnes používán velice často, ovšem v řadě případů může být zdrojem i celé řady problémů.
Co se například stane ve chvíli, když ve velmi pozdní fázi projektu zjistíme, že danou část programu je třeba urychlit (a tudíž realizovat v hardwaru). V tu chvíli nemusí být připravené rozhraní mezi hardwarem a softwarem již dostatečné a další iterace s návrhem nového hardwaru a následnou validací bude mít zcela jistě negativní dopad na harmonogram celého projektu.
Pojďme se zamyslet nad tím, do jaké míry je v klasickém provedení návrhu pro vývoj akcelerace uvnitř FPGA třeba řady odborných znalostí (v oblasti jazyků, návrhu a metodiky ověření). Již dříve jsme se však zmínili o požadované metodice a doprovodných nástrojích, které pomáhají při transformaci zdrojového kódu do logických hradel. S jejich pomocí mohou softwaroví inženýři sami vyvíjet bloky hardwarových akcelerátorů, které potřebují pro svůj software. Výsledkem takového přístupu je kratší doba vývoje.
Naše myšlenky vedou k pojmu „platforma“ a cílem je přinést optimální platformu vývoje software. Platformu, která musí být navržena ve spolupráci s hardwarovými inženýry a využívá jejich odborných znalostí, ovšem jakmile je navržena, tak ji mohou zcela převzít softwaroví inženýři a přidat vlastní bloky urychlovačů a další díly, potřebné k dokončení software s využitím dříve požadovaných „C-2-Gates“ nástrojů. Díky takovému prostředí mohou softwaroví inženýři dokončit vývoj software i návrh FPGA zcela bez hlubších znalostí návrhu FPGA obvodů. Na obr. 4 je uveden příklad takové platformy.
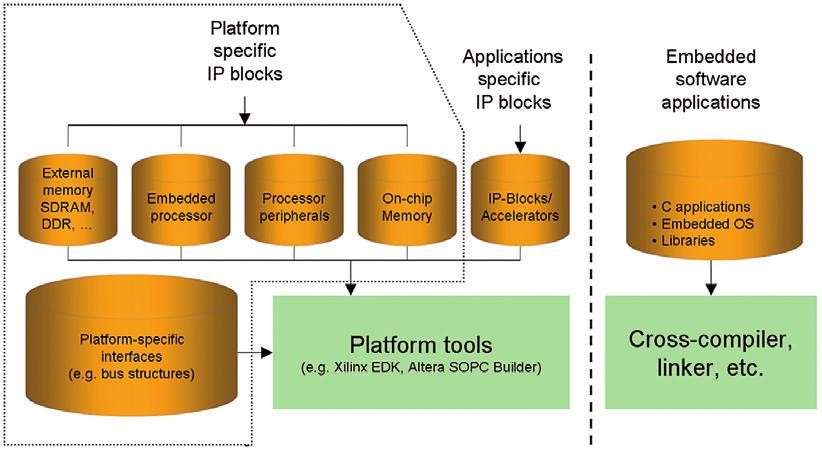
Obr. 4 Obvod FPGA jako platforma
Podmínkou je, že již při vytváření platformy s FPGA musí být rozhodnuto, které procesorové jádro bude v aplikaci použito (pokud má být v aplikaci použito), včetně představy o jeho konfiguraci, rozhraní pro komunikaci s vnějším světem a vůbec periferiích a rozhraní, které budou v zařízení použity (I2C, Ethernet, PCI…). Rovněž nesmíme zapomenout ani na typ použité paměti (Flash, SDRAM, DDR…) a celé řady dalších prvků.
Výrobci hradlových polí jako jsou Xilinx a Altera mají platformy („Studio“ a „SOPC-Builder“), umožňující rychlou konfiguraci generování základu těchto platforem. Za tímto účelem získá uživatel rovněž přístup k velké podpoře ověřených IP jader, které lze použít jako plug and play moduly. Implementovaná platforma mikrokontroléru má k dispozici velké množství zdrojů a může plně spolupracovat s požadavky softwarového týmu.
„ImpulseC“ od Impulse Accelerated Technologies je rozšíření ANSI-C k možnosti popisu hardware a paralelních procesů pomocí jazyka C:
Účel uvedeného rozšíření je jasný – využití jazyka C k popisu hardwaru. Tedy o něco, k čemu původně nebyl nikdy určen, a to včetně popisu souběžných procesů či přesných aritmetických operací. Nicméně je zde hlavní rozdíl také v ceně. Aplikace algoritmů do logických hradel stojí, na rozdíl od aplikace na úrovni software, peníze. Proto máme zájem o takový popis hardware na úrovni jazyka C, který nám v křemíku zajistí cenově efektivní implementaci. Vezměme si jako příklad 12 bitů širokou datovou cestu. Určitě nechceme, aby byla zcela zbytečně implementována za použití 32bitové aritmetiky. Dalším příkladem mohou být i různé extrakční operace, které například z 8 až 12 bitových slov vytvářejí bloky s nižším počtem bitů. Na úrovni hardware se jedná o velmi jednoduchou implementaci (pouze stačí vhodně nakonfigurovat několik vodičů), ovšem na softwarové úrovni jde o poměrně složitou formulaci pomocí jazyka C. Pokud mikroprocesor neobsahuje nějaké zvláštní instrukce, nevyhneme se použití množství AND a SHIFT operací.
„CoDeveloper“ je integrované vývojové prostředí (kompilátor, simulátor, analytický nástroj), který je schopen výsledek ImpulseC kódu v jazyce C převést do podoby VHDL nebo Verilog (jazyka, používaného pro popis hardware při konfiguraci FPGA).
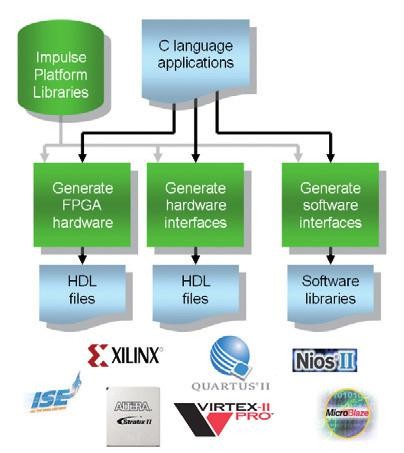
Obr. 5 Struktura vývoje s CoDeveloper
Obr. 5 ukazuje strukturu vývoje aplikace za použití CoDeveloper. Kód v jazyce C lze sestavit do několika různých stylů, takže lze generovat jak obecný VHDL/Verilog kód, tak i specifický kód pro danou rodinu FPGA obvodů. Vzhledem k tomu, že různá hradlová pole nabízejí různé možnosti připojení „urychlovacích bloků“ k procesorové implementaci, lze i zde nastavit typ rozhraní, které má být vygenerováno. Rozhraním přitom myslíme i ty, které se používají pro připojení periferních prvků a pamětí, ale některé procesory podporují i použití vysokorychlostních rozhraní pro výměnu dat mezi procesory a externími obvody (například akcelerátory). CoDeveloper rovněž zajišťuje také generování všech potřebných softwarových ovladačů v C nebo assembleru, které jsou potřeba pro čtení a zápis z aplikační vrstvy programového vybavení embedded procesoru.
Vraťme se však nyní na začátek našeho článku, k příkladu aplikace regulačního obvodu, kde využijeme novou strukturu vývoje.
V konkrétním případě byl kód jazyka C vytvořen za pomocí generátorů Matlab/Simulink/TargetLink, jako výsledek modelování daného algoritmu. Cílem bylo získání zdrojového kódu pro platformu FPGA s integrovaným procesorem. Na procesoru by měl běžet nějaký operační systém (zajišťující čtení a zápis hodnot z A/D a D/A převodníků, datových rozhraní a se správou celého systému) s jádrem výpočetního algoritmu a regulační smyčka by měla být realizována na úrovni hardware.
V prvním kroku je nutné si ověřit, že zdrojový kód získaný z generátoru může být automaticky přeložen do VHDL. V praxi se ukazuje, že jsou obvykle potřeba jen drobné úpravy. Například na volání funkce a způsob, jakým dochází k výměně parametrů mezi hardware a software, který plnil potřeby simulace. V podstatě se nedá předpokládat, že vygenerovaný kód v C by mohl být ihned automaticky přeložen, vždy je nutné provést drobné kódové úpravy. Mezi hlavní problémy, které zabraňují automatickému překladu kódu, patří:
V dalším kroku, jakmile byl zdrojový kód C vyladěn do vhodné podoby, jej vložíme do CoDeveloper a výsledkem bude RTL (Register Transfer Level) kód v jazyce VHDL. Ten je třeba dále zpracovat vhodným syntezátorem (nástrojem, který se používají pro návrh FPGA), aby mohl být přeložen do struktury logických hradel.
Dále je třeba dostat všechny potřebné bloky rozhraní, vytvořené pro připojení kontrolního akcelerátoru, přímo na embedded procesor. Stejně tak je nutné vygenerovat i potřebné softwarové ovladače.
Závěrečné zprávy z kompilátorů nám nabízejí velké množství informací o latenci a datové propustnosti, kterou lze ve výsledném systému očekávat. Výchozí nastavení nástroje pro vytvoření hardwarové architektury využívá velké množství hodinových cyklů, proto je vhodné nastavit CoDeveloper pro použití techniky jako je „pipelining“ a „loop-unrolling“, které jsou výslednou implementaci schopny generovat s vyšším výkonem. Prostřednictvím zkušební implementace lze nyní ověřit, zda je získaný hardwarový blok schopen splnit všechny výkonnostní požadavky dané aplikace.
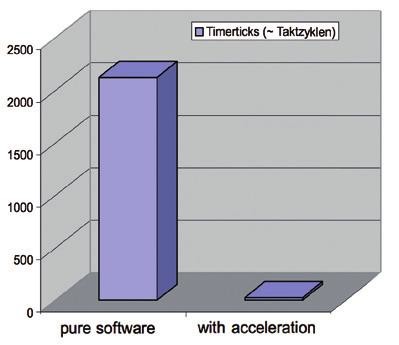
Obr. 6 Čas vykonání daného algoritmu s a bez hardwarové akcelerace
V tuto chvíli již máme k dispozici kompletní návrh realizace systému na obvodech FPGA i výsledky základního benchmarku. Pod jakýmsi pseudokódem máme nyní popsanou strukturu čisté softwarové implementace, využívající při provozu akceleračních bloků.

Operace „co_stream_read()“ je tzv. blokující. To znamená, že vyžaduje synchronizaci mezi bloky hardware a prvky na straně software, aby byla schopna dodat vhodný výsledek. Samozřejmě, pokud má aplikace k dispozici informaci o čase, který pro svou činnost potřebuje hardwarový blok akcelerátoru, může mezi tím obsloužit jiné části systému.
Výsledek praktického benchmarku byl následující. Čistě softwarové zpracování algoritmu vyžadovalo 2120 hodinových cyklů. Naproti tomu zpracování za pomocí hardwarového akcelerátoru vyžadovalo pouze 27 hodinových cyklů. To znamená, že danou aplikaci se podařilo zrychlit zhruba 78krát.
Vezměme nyní uvedený příklad aplikace a podívejme se na vývoj celého systému stylem kombinace hardwarových a softwarových prostředků. Cílem je samozřejmě dosažení vyšší rychlosti běhu.
Krok 1:
Krok 2:
Krok 3:
V tomto článku jsme se pokusili přiblížit možnosti nasazení FPGA obvodů do aplikací, kde je žádoucí rychlý běh software a to jak s, tak i bez integrovaného embedded procesoru ve struktuře FPGA. S uvedenou metodikou a zmíněnými nástroji mohou softwaroví inženýři nyní efektivně využívat schopnosti FPGA a to i s velmi malou či dokonce žádnou znalostí speciálních jazyků pro popis hardware. Nakonec i využití jazyka C pro popis hardwaru nám pomůže zvýšit úroveň abstrakce, což ve výsledku vede ke zkrácení vývojových cyklů a rychlejšímu uvedení nového zařízení na trh.
Nadějí do budoucna je dostupnost ještě užší integrace nástrojů na systémové úrovni, které by byly schopny kompilovat kód z jazyka C i do jiných formátů. Myslím si, že našim společným přáním by byl ideální stav, kdy bychom mohli například zcela automaticky generovat hardwarovou strukturu ze zdrojového kódu jazyka C. Do jaké míry se nám přání splní a systémové nástroje budou schopny generovat přímo složení logických hradel, ukáže až čas.














