

 Vítejte, dnes je
pátek
25.
duben
2025
Vítejte, dnes je
pátek
25.
duben
2025
Citát: „Co není měřeno, pravděpodobně nebude uděláno,“ není zaměřen (jenom) proti (líným) lidem, ale především na postup tvorby, podobně jako pořekadlo dvakrát měř, jednou řež (řeš v případě HDL). Obě rčení nám naznačují, že bez dostatečného měření nedosáhneme požadovaného výsledku, což v případě programování platí stejně dobře, ne-li více než v jiných oblastech. HDL programování toto pravidlo potvrzuje, přestože jeho testování v rámci laboratoře (vývoje prototypu) může být nejen finančně náročné, ale naprogramovaný obvod nedosahuje pozorovatelnosti a řiditelnosti napsaného kódu.
Pojmy pozorovatelnosti a řiditelnosti jsou poměrně zásadní v pohledu na testovaný kód. Pozorovatelnost popisuje schopnost sledovat, jak které prvky reagují na různé stimuly (podněty, vstupy). Řiditelnost je schopnost dosahovat požadovaných stavů systému (výstupů) pomocí definovaných vstupů.
Dalším důležitým pojmem je testbench (v doslovném překladu testovací stolice), jedná se o (nejlépe univerzální) testovací (budicí) sekvenci vstupů (stimulus) pro DUT, která ověří všechny možné stavy zařízení. Testbench by měl generovat takový stimulus (takové vstupy), aby aktivoval případnou chybu, aby všechny efekty této chyby byly propagovány na sledované výstupy (pozorovatelnost) a aby tyto výstupy byly zachyceny a detekovány jako chyby. Z toho plyne nemožnost mít naprosto univerzální kód pro otestování více projektů. V současnosti je problém i v přenositelnosti testovacího kódu mezi platformami.
V případě simulování (testování) kódu máme lepší přístup (řiditelnost) než při testování již realizovaného, kódem popsaného obvodu. Můžeme dokonce přímo určit, která část kódu je chybná, i to, které části (ne)byly otestovány (provedeny). Dostáváme se tak zpět k měření zmíněnému v úvodu a konečně i k pojmu coverage (anglicky pokrytí), který v HDL odkazuje k metrice měření úplnosti ověření funkce (verifikace) kódu. Coverage popisuje, jaká část kódu byla (úspěšně) provedena (aktivována) během testování a která část otestována (provedena) nebyla.
Existuje více druhů coverage, například v kódu se 100% pokrytím Code Coverage (anglicky pokrytí kódu) byl spuštěn každý příkaz, ale ani to nemusí znamenat, že byly odhaleny všechny chyby. Code Coverage nedává jinou informaci, než jestli byl příkaz spuštěn. Tato metrika je používána především pro jednoduchost zavedení, je proveditelná automaticky. Podobně jako další strukturální (a nikoliv funkční) metriky je v simulačních HDL prostředích, jako například v ModelSimu, prováděna automaticky, při simulaci kódu. Program vám tedy na konci testování samovolně označí, které řádky (příkazy/ statement) kódu byly spuštěny, stačí toto měření před simulací zapnout.
Typů Code Coverage je hned několik, dělí se podle toho, u které části kódu sledujeme, zda byla spuštěna. Toggle Coverage počítá, kolikrát byla hodnota každého bitu registru změněna. Obvykle je velice časově náročné věnovat se všem bitům, nicméně pro určité typy se hodí informace, že byla programem změněna jejich hodnota.
Line Coverage indikuje, kolikrát byly jaké řádky kódu spuštěny (viz obr. 1). Statement Coverage podává informaci o příkazech, tudíž je o něco přesnější než Line Coverage. Naopak na větší část programu je zaměřena Block Coverage, která indikuje, zda byl proveden kód v bloku. Blok může být kód ohraničený podmínkami nebo procedura. Jakmile je dosaženo tohoto bloku, jsou všechny řádky v něm považovány za provedené.
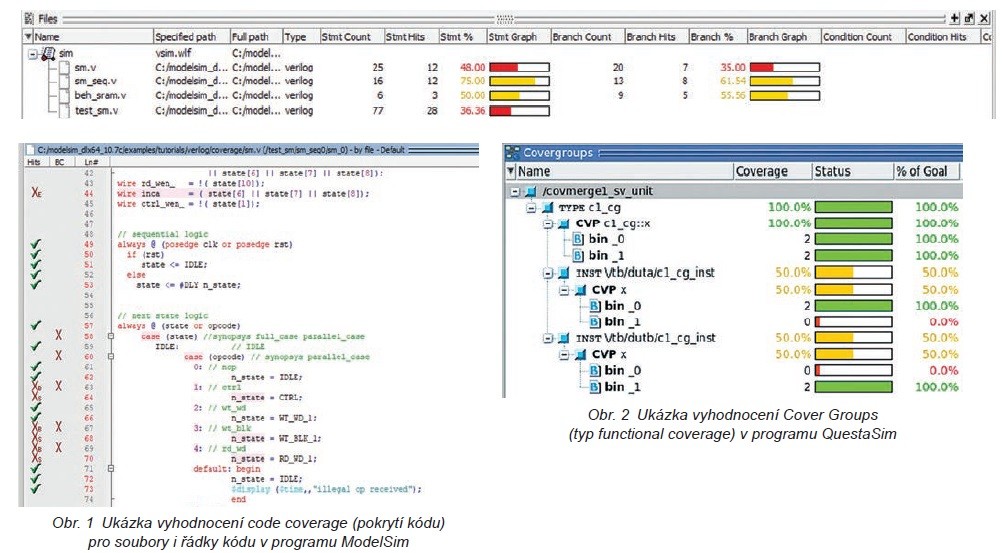
Branch Coverage nebo také Decision Coverage poskytuje informaci, kolikrát logický výraz v podmínce dosáhl které z hodnot pravda (true) a nepravda (false). Expresion Coverage potom přesněji testuje zvlášť každý operand logické operace a podává informaci, zda dosáhl obou možných hodnot. FSM Coverage počítá, jak a kolikrát se změnil stav konečného automatu.
Ověření nejenom toho, že část kódu byla spuštěna, ale i toho, že dává zamýšlený výsledek, již vyžaduje interakci uživatele. Ten musí zformovat postup (coverage model), které hodnoty zkontrolovat po kterých krocích. I s tímto typem coverage může pomoci vývojové prostředí. Například QuestaSim nabízí schopnosti zobrazit napsaný kód jako logické schéma, náhled do paměti v každém kroku běhu programu nebo náhodnou změnu (randomizaci) vstupních parametrů a posloupnosti dalších vstupů.
Přístupem constrained-random (anglicky „omezená náhoda“), tedy generování náhodných modifikací stimulu podle určitých pravidel, lze generovat tisíce testů, které by jinak vyžadovaly mnoho manuální práce. Takový přístup nedává přesnou informaci, co bylo otestováno, na rozdíl od manuálně vytvořeného testu pro ověření jedné zamýšlené funkce. Functional Coverage proto může být také chápána jako měření, jaké funkce zapsané v kódu byly ověřeny. Existují mechanismy zpětně (po dokončení simulace) informující o provedení a ověření dané funkce (předpokládané posloupnosti vstupů a výstupů).
Nejjednodušší typ Functional coverage – Cover Group Modeling – spočívá v ověření hodnot skupiny proměnných (signálů, registrů, …) v určitý čas, po určitém kroku. Slouží k ověření, zda na pozorovaných skupinách (anglicky group) je správná kombinace hodnot (např. při zápisu do paměti správné nastavení signálů zápisu, řízení, adresy, …).

Komplikovanější je potom pojetí Cover Property Modeling, tedy kontrola následností v sekvenci hodnot a událostí. Nejčastěji se používá pro ověření správného sledu událostí při navazování komunikace a nastavení parametrů kanálu (handshake).
V kombinaci oba typy dávají celkem přesnou představu o klíčových schopnostech testovaného zařízení. Lze pomocí nich sestavit stavový diagram celého programu a pomocí coverage zjistit, zda se jím prochází podle požadavků.
Dalším krokem ve vývoji simulace by měl být přenositelný stimulus. Tedy možnost otestovat zařízení stejným vstupem na více platformách, na více úrovních abstrakce a stejně tak v pozdější fázi vývoje použít stejný postup i na jeho reálnou reprezentaci.
I přes nástroje pro důkladné otestování kódu popsané výše nejsou většinou odhaleny všechny chyby. Vhled, tedy řiditelnost a pozorovatelnost poskytnutou vývojovými a simulačními nástroji, jako je program ModelSim nebo jeho vybavenější verze QuestaSim, nestačí. Je potřeba dalších informací, jak se orientovat ve výsledcích poskytovaných simulačním prostředím a co nám říkají.
Složitost popisovaných obvodů většinou přesahuje lidské schopnosti nalezení chybné části kódu i v případě, že zaznamenáme nesprávné výsledky. Eliminace závad bez simulačních nástrojů může vést k chybám, které odhalí až uživatel nebo ještě hůře způsobí nějakou nehodu v provozu.














